Vibe Coding IA Programmation
Building AI Agents in Kotlin – Part 5: Teaching Agents to Forget
JetBrains AI Blog ·
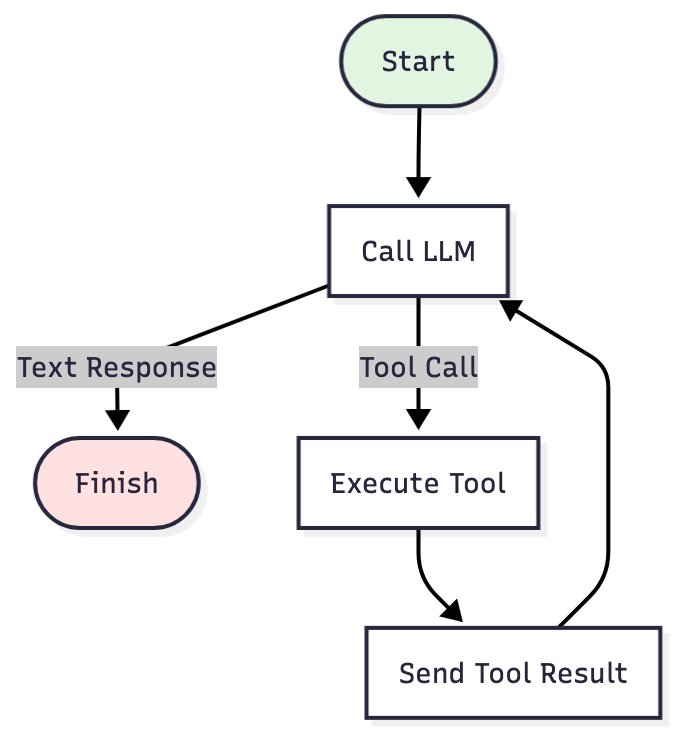
Previously in this series: Agents eventually run out of context. When they do, they crash, and you lose everything mid-task. We’ve been running GPT-5 Codex since Part 1. It scores 0.58 on SWE-bench Verified. We tried Claude Sonnet 4.5 next, which scored 0.6 and ran faster on most tasks. But complex…